| Input Semantics | GVSNet (Ours) |
SPADE[1]+SM[2] | SPADE[1]+CVS[3] | |||

|

|

|

|
|||

|

|

|

|
|
|
|
|
|
1 TU Kaiserslautern | 2 Google Research | 3 NVIDIA | 4 DFKI Kaiserslautern |
| Input Semantics | GVSNet (Ours) |
SPADE[1]+SM[2] | SPADE[1]+CVS[3] | |||
|
|
|
|
|
|||
|
|
|
|
|
|
Content creation, central to applications such as virtual reality, can be a tedious and time-consuming.
Recent image synthesis methods simplify this task by offering tools to generate new views from as little
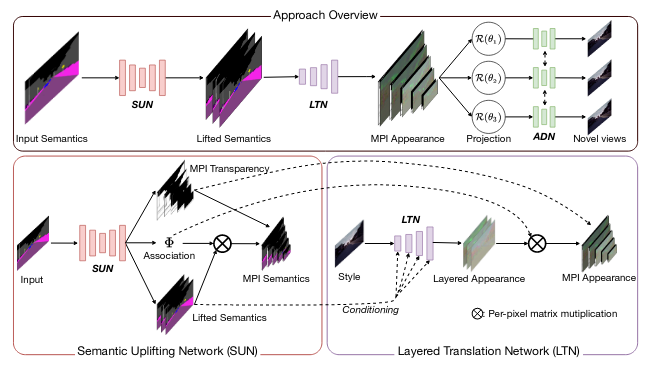
as a single input image, or by converting a semantic map into a photorealistic image. We propose to push
the envelope further, and introduce Generative View Synthesis (GVS), which can synthesize multiple photorealistic views
of a scene given a single semantic map. We show that the sequential application of existing techniques, e.g., semantics-to-image
translation followed by monocular view synthesis, fail at capturing the scene's structure. In contrast, we solve the semantics-to-image
translation in concert with the estimation of the 3D layout of the scene, thus producing geometrically consistent novel views that preserve
semantic structures. We first lift the input 2D semantic map onto a 3D layered representation of the scene in feature space, thereby preserving
the semantic labels of 3D geometric structures. We then project the layered features onto the target views to generate the final novel-view images.
We verify the strengths of our method and compare it with several advanced baselines on three different datasets. Our approach also allows for style
manipulation and image editing operations, such as the addition or removal of objects, with simple manipulations of the input style images and semantic maps respectively.
|
 |
 |
Tewodros Habtegebrial, Varun Jampani, Orazio Gallo, Didier Stricker. Generative View Synthesis: From Single-view Semantics to Novel-view Images Arxiv Preprint, 2020. Link |
| References |
| [1] SPADE: Semantic Image Synthesis with Spatially-Adaptive Normalization, Park et al. link |
| [2] SM: Stereo Magnification: Learning View Synthesis using Multiplane Images, Zhou et al. link |
| [3] CVS: Monocular Neural Image Based Rendering with Continuous View Control, Chen et al. link |
|
We thank the SDS department at DFKI Kaiserslautern, for their support with GPU infrastructure. The template for this website is borrowed from Richard Zhang. |